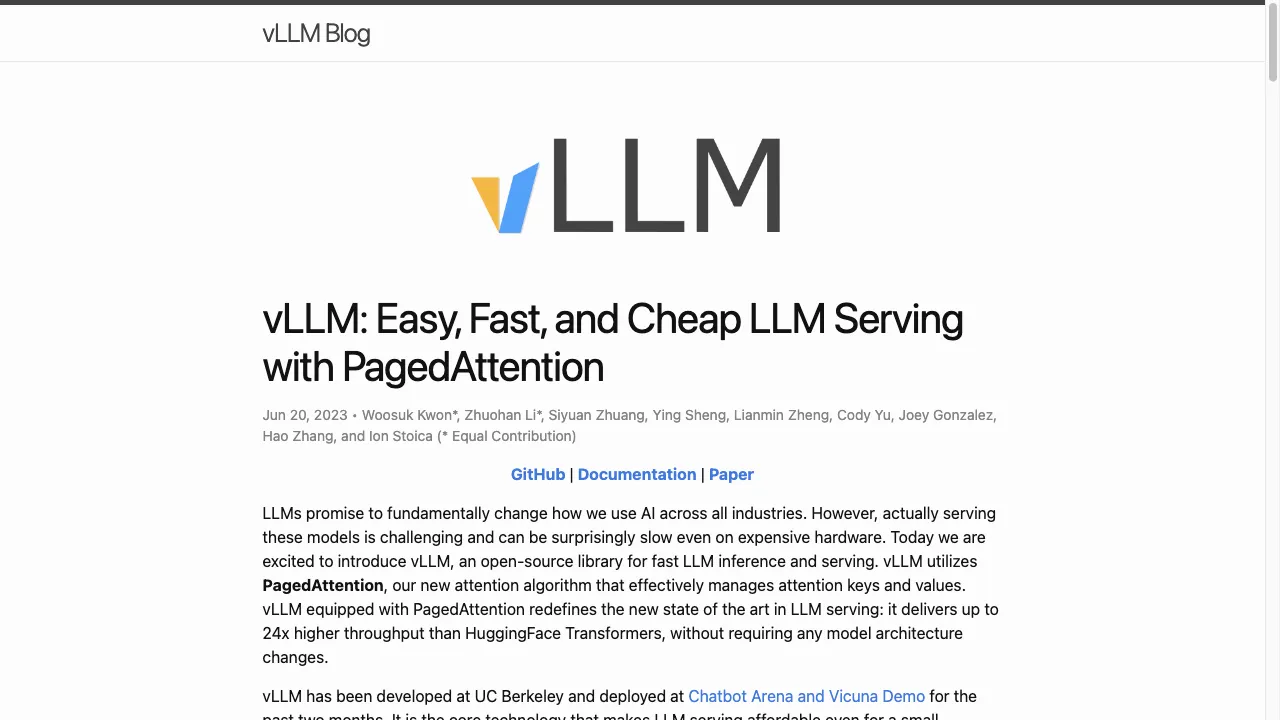
Was ist vLLM?
Das vLLM-Projekt stellt einen bedeutenden Fortschritt in der Bereitstellung und Verwaltung großer Sprachmodelle (LLMs) dar. Es zielt darauf ab, die Leistung, Skalierbarkeit und Kosteneffizienz von LLMs zu optimieren, um sie für verschiedene Anwendungen zugänglicher und effizienter zu machen. Dieser Bericht bietet eine detaillierte Analyse von vLLM, einschließlich seiner Beschreibung, Funktionen, Anwendungsfälle, Nutzungshinweise, Vor- und Nachteile sowie Überlegungen und Bewertungen. Die Informationen stammen aus mehreren zuverlässigen Quellen, um ein umfassendes Verständnis von vLLM zu gewährleisten.
vLLM Traffic-Analyse
vLLM Monatliche Besuche
vLLM Top besuchte Länder
vLLM Top-Schlüsselwörter
vLLM Website-Traffic-Quellen
vLLM Funktionen
PagedAttention
Der PagedAttention-Mechanismus ist eine innovative Aufmerksamkeitsalgorithmus, der Speicherengpässe überwindet, indem er den Key-Value-Cache in feste Blöcke partitioniert. Dies ermöglicht eine nicht zusammenhängende Speicherung und bedarfsgerechte Zuteilung, was die Effizienz bei der Inferenz verbessert.
Effiziente Speicherverwaltung
vLLM verwendet verschiedene Optimierungen wie kontinuierliche Batchverarbeitung und optimierte CUDA-Kernels, um die Inferenzgeschwindigkeit zu erhöhen und die Modellgröße zu reduzieren, ohne die Genauigkeit zu beeinträchtigen.
Kompatibilität mit OpenAI API
Die API-Struktur von vLLM ist mit der von OpenAI vergleichbar, was den Entwicklern den nahtlosen Übergang zu vLLM erleichtert, ohne dass sie ihre bestehenden Tools wesentlich ändern müssen.
vLLM Vorteile
Schnellere Antwortzeiten
vLLM reduziert die Inferenzzeiten erheblich, was zu einer reaktionsschnelleren und benutzerfreundlicheren Erfahrung für LLM-Anwendungen führt.
Skalierbarkeit
Die effiziente Speicherverwaltung von vLLM ermöglicht die Handhabung größerer Modelle und erhöht die Arbeitslast, was es für reale Bereitstellungen geeignet macht.
Reduzierte Kosten
Schnellere Inferenz führt zu niedrigeren Betriebskosten, insbesondere bei der Bereitstellung von LLMs in Cloud-Umgebungen.
vLLM Nachteile
Komplexität
Die Implementierung von vLLM kann ein tieferes Verständnis seiner Architektur und Optimierungen erfordern, was für Entwickler, die neu in der Bereitstellung von LLMs sind, eine Hürde darstellen könnte.
Begrenzte Modellunterstützung
Derzeit unterstützt vLLM nur eine begrenzte Anzahl von Modellen, obwohl kontinuierlich neue Modelle hinzugefügt werden.
Verwendung vLLM
Step 1: Installation von vLLM
Um vLLM zu installieren, folgen Sie den Anweisungen in der Dokumentation auf der offiziellen vLLM-Website. Stellen Sie sicher, dass Sie die erforderlichen Abhängigkeiten und die richtige Umgebung eingerichtet haben.
Step 2: Server starten
Starten Sie den vLLM-Server mit dem Befehl 'vllm serve'. Standardmäßig wird der Server auf 'http://localhost:8000' gestartet, aber Sie können die Adresse mit den Argumenten '--host' und '--port' angeben.
Step 3: Erste API-Anfrage
Nach dem Start des Servers können Sie Ihre erste API-Anfrage an den Endpunkt 'create completion' senden, um die Funktionsweise von vLLM zu testen.
Wer es nutzt vLLM
Chatbots und virtuelle Assistenten
vLLM verbessert die Leistung von Chatbots und virtuellen Assistenten, indem es ihnen ermöglicht, nuancierte Gespräche zu führen und komplexe Anfragen zu verstehen, was zu schnelleren Reaktionszeiten führt.
Effiziente NLP-Modellbereitstellung
Mit vLLM können Organisationen ihre Sprachmodelle effizienter bereitstellen und nutzen, was zu mehr Innovation und Effizienz in NLP-Anwendungen führt.
Großangelegte Bereitstellungen
Die Skalierbarkeit von vLLM macht es ideal für den Einsatz in realen Anwendungen, die große Modelle und hohe Arbeitslasten erfordern.
Kommentare
"vLLM hat meine Erwartungen übertroffen! Die Leistung ist unglaublich und die Integration war einfach. Ich kann es jedem empfehlen."
"Die Dokumentation ist sehr hilfreich, und ich konnte schnell loslegen. Die Geschwindigkeit der Inferenz ist beeindruckend!"
"Ich habe vLLM in meinem Projekt verwendet und bin mit den Ergebnissen sehr zufrieden. Es hat die Effizienz meiner Anwendung erheblich verbessert."
Referenzen
- [1] Was ist vLLM und welches Problem löst es?.URL:https://collabnix.com/what-is-vllm-and-what-problem-does-it-solve/on: 5/18/2024
- [4] Wie optimiert vLLM das LLM-Servierungssystem?.URL:https://medium.com/cj-express-tech-tildi/how-does-vllm-optimize-the-llm-serving-system-d3713009fb73on: 4/23/2024
- [5] Was ist vLLM und wie implementiert man es?.URL:https://blog.monsterapi.ai/blogs/what-is-vllm-and-how-to-implement-it/
- [6] Optimierung der LLM-Bereitstellung: vLLM PagedAttention und die Zukunft des effizienten AI-Serving.URL:https://www.unite.ai/optimizing-llm-deployment-vllm-pagedattention-and-the-future-of-efficient-ai-serving/on: 7/22/2024
vLLM Alternativen
Ein fortschrittliches zweisprachiges Dialogmodell.
Metas neuestes großes Sprachmodell verbessert die KI-Fähigkeiten.
Ein KI-Chatbot von OpenAI für vielseitige Anwendungen.
Ein führender Übersetzungsdienst mit fortschrittlicher Technologie.
Innovative AI hardware solutions for hohe Leistung.
Innovative Plattform für KI-gesteuerte Chatbots mit Fokus auf Erwachsenenunterhaltungen.
Ein führendes KI-Forschungslabor von Google.
Eine innovative Plattform für generative KI-Modelle.
Interaktive KI-Chat-Plattform für Gespräche mit Charakteren.
Ein innovatives KI-gestütztes Notizbuch von Google.
Innovative Plattform zur Integration mehrerer KI-Chat-Assistenten.
Eine Plattform für kostengünstige Cloud-Computing-Dienste.
Eine innovative Plattform zur Entwicklung von KI-Anwendungen.
Eine innovative Plattform für lokale Sprachmodelle.
Eine umfassende Analyse des Llama 2 Modells von Meta AI.
Kostenloser Zugang zu ChatGPT für alle Nutzer.